.svg)

Data needs direction: five clarifications for database design

Sometimes a new computational paradigm can be better defined by abolishing distracting capabilities than by adding new capabilities. For example, Edsger Dijkstra paved the way for structured programming by arguing for abolishing the use of GOTO statements in programming languages (see his 1968 letter “Go To Statement Considered Harmful”). The constructs for structured programming had already existed but the paradigm shift needed the extra push by stamping out the anti-patterns enabled by GOTOs. Today’s high-level programming languages lack the very concept of GOTO.
DataJoint is a full-featured relational database programming language; it replaces SQL for defining and querying structured data. DataJoint implements a new form of the relational data model that is more semantically refined to make schema design clearer while retaining the full capabilities and rigor of the relational data model. It makes good design practices more obvious and bad design choices harder or impossible.
In this story, let me illustrate five of DataJoint’s clarifications that make database work more rigorous and teachable.
Clarification 1: Primary key not optional
SQL sees no problem defining a table with no primary key thereby failing to enforce the foundational premise of the relational model that all tables must represent sets (unordered collections of unique elements). DataJoint’s syntax makes it impossible to not define a primary key. For example, the table definition below is perfectly legal in SQL.
CREATE TABLE person (
person_id int,
first_name varchar(30),
last_name varchar(30))
A better design would define the primary key and make the required columns not null, resulting in this longer code:
CREATE TABLE person (
person_id int NOT NULL,
first_name varchar(30) NOT NULL,
last_name varchar(30) NOT NULL,
PRIMARY KEY (person_id))
The same definition in DataJoint would appear as follows. We use Python as the host language in all examples.
@schema
class Person(dj.Manual):
definition = """
person_id : int
---
first_name : varchar(30)
last_name : varchar(30)
"""
The divider --- separates the primary key fields above from the secondary attributes below. There is no option to omit defining a primary key. All attributes are required by default and are not nullable. SQL made a terrible choice to make fields nullable by default.
Clarification 2: Missing values, defaults, and nulls.
The second clarification concerns the use of optional attributes. A field (or attribute) is optional if specifying its value is not required when inserting new data. In SQL, this is possible when either a default value is provided or the field is nullable. NULL is not just a special value; its logic is handled quite differently from all other values. A point of confusion is that in SQL a field can be nulllable and it may have a non-null default value.
For example, in the following definition the field quantity is both nullable and has a default value of 100.
CREATE TABLE order_item (
order_id int NOT NULL,
item_id int NOT NULL,
quantity int DEFAULT 100
PRIMARY_KEY (order_id, item_id),
FOREIGN KEY (order_id) REFERENCES order (order_id),
FOREIGN KEY (item_id) REFERENCES item (item_id))
Then an INSERT omit a value would result in the use of the default value of 100. The client would also have the option to insert NULL to indicate the missing value. This creates many confusing choices and behaviors. While this abundance of choices may find its use, more often than not, it multiplies confusion as we must juggle multiple definitions of the term “missing value.”
In DataJoint, one makes a field nullable by setting its default to null. This sidesteps many problems of definitions and use of missing values.
The behavior is simple: if a value is missing, then the default is used. If the default is null, then the value is nullable. You can use either of two definitions:
# Definition 1
@schema
class OrderItem(dj.Manual):
definition = """
-> Order
-> Item
---
quantity = 100 : int
"""
or
# Definition 2
@schema
class OrderItem(dj.Manual):
definition = """
-> Order
-> Item
---
quantity = null : int
"""
In the first definition, quantity is not nullable and defaults to 100; in the second, it is nullable and it defaults to null. We give up the flexibility to provide a non-null default to a nullable field but it’s a sacrifice well worth the clarify of definitions, communication, and insert behavior.
As an aside, in general, the number of nullable attributes should be small in well-designed schemas. If many attributes are nullable, this probably means that they are defined in the wrong table and an extra table must be defined to represent entities for which these attributes are required and therefore not nullable.
Clarification 3: Foreign keys reference the primary key
Nearly always, the foreign key must reference the primary key attributes of the parent table and the foreign key attributes in the child table must have the same types as the primary key attributes in the parent table, listed in the same order in the foreign key declaration. That’s quite a bit of complexity to track. Yet SQL syntax makes no effort to simplify this most common use. The syntax for an invalid foreign key referencing a secondary non-unique attribute is indistinguishable from a well-formed foreign key. Changing the primary key in the primary key requires concomitant changes of all the foreign key attributes in all the referencing child tables.
DataJoint abolishes this complexity by requiring the foreign key to always reference the primary key and automatically introduces required foreign key attributes with correctly matching definitions. Let’s define the table FilledItem referencing the OrderItem table defined above.
SQL first:
CREATE TABLE filled_item (
order_id int NOT NULL,
item_id int NOT NULL,
fill_date date NOT NULL,
PRIMARY KEY (order_id, item_id),
FOREIGN KEY (order_id, item_id) REFERENCES order_item(order_id, item_id)
)
The equivalent definition in DataJoint is
@schema
class FilledItem(dj.Manual):
definition = """
-> OrderItem
---
fill_date : date
"""
DataJoint removes the flexibility to define foreign keys referencing anything other than the primary key but greatly simplifies both the syntax, shortens the learning process, and reduces opportunities for error.
Clarification 4: No cyclic dependencies
One of the most significant simplifications in DataJoint is the elimination of cyclic dependencies in database schemas. All database schemas designed with DataJoint must constitute Directed Acyclic Graphs (DAGs).
To illustrate, let’s consider the Sakila database for a DVD rental shop provided in the MySQL documentation and used by many tutorials.
Here is its Enhanced Entity Relationship Diagram:
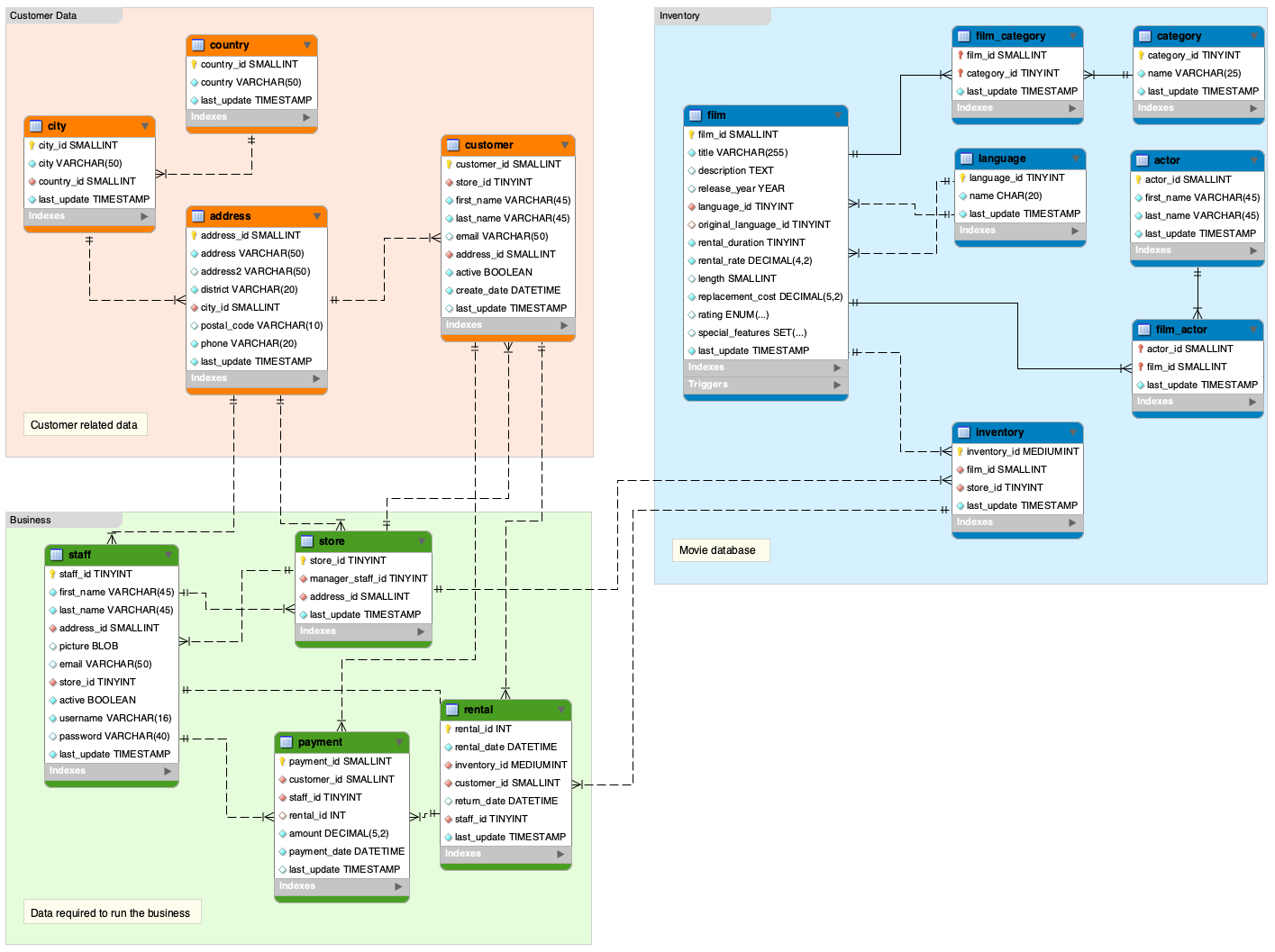
The schema has a cyclic dependency. Can you spot it?
After setting up the database, we can connect to it with DataJoint and interact with its individual tables.
However, when attempting to plot the Diagram, DataJoint raises the error indicating that it cannot handle cyclic dependencies.
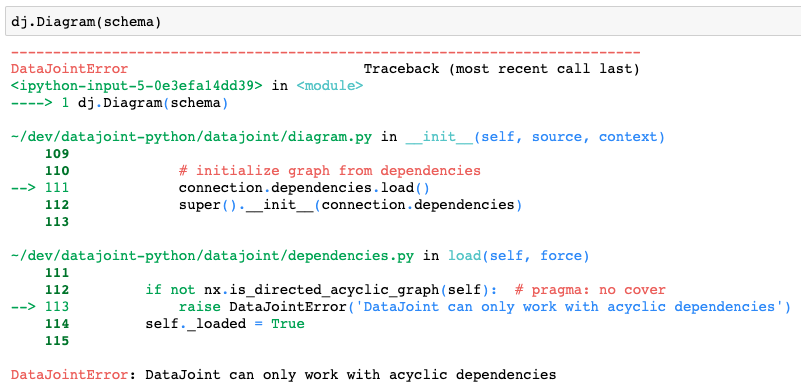
The cycle is introduced between the staff and store tables where each staff references the store and each store references its manager from the staff.
To break the cycle, we drop the manager foreign key and plot the diagram.
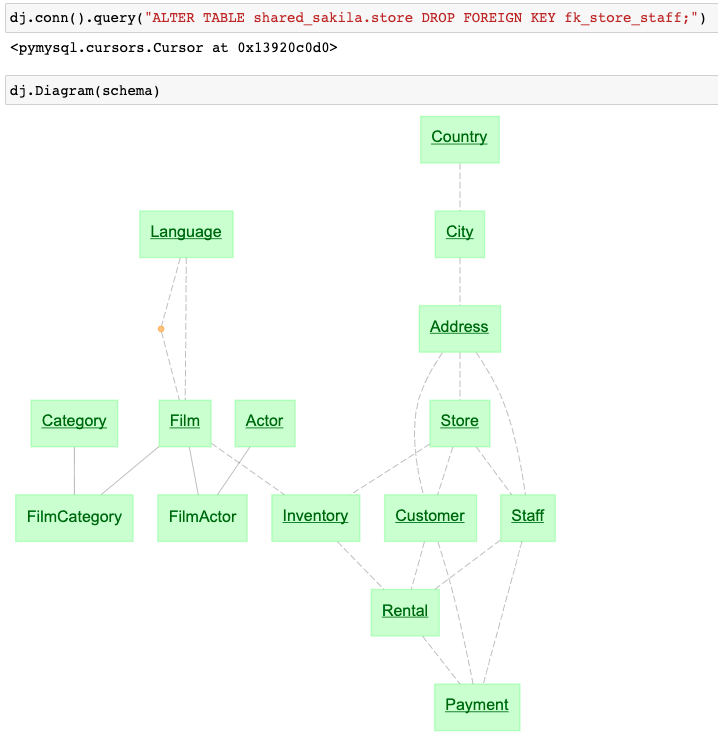
In Jupyter, hovering over the tables in the diagram will show their detailed definitions in DataJoint declaration notation.
Compare the EER diagram above and the DataJoint diagram. What stands out? Which is more amenable for rapid comprehension?
DataJoint schema designs have a direction. To populate the data, you start from the top of the diagram and move down step by step. In this way, the database schema also expresses the workflow for data collection and analysis. Having worked with hundreds of DataJoint schemas for 13 years, it now pains me to have to figure out a non-directional schema as shown in the conventional EER above. Databases need a sense of direction to help orient their users and designers.
But did we lose any representational power? Is there a way to represent managers for stores referencing the staff? It turns out that any cyclic dependency can be replaced with an equivalent acyclic design, which may require an additional to represent the relationship.
Thus we add the table StoreManager to the schema:
@schema
class StoreManager(dj.Manual):
definition = """
-> Store
---
-> Staff
"""
And the diagram beccomes
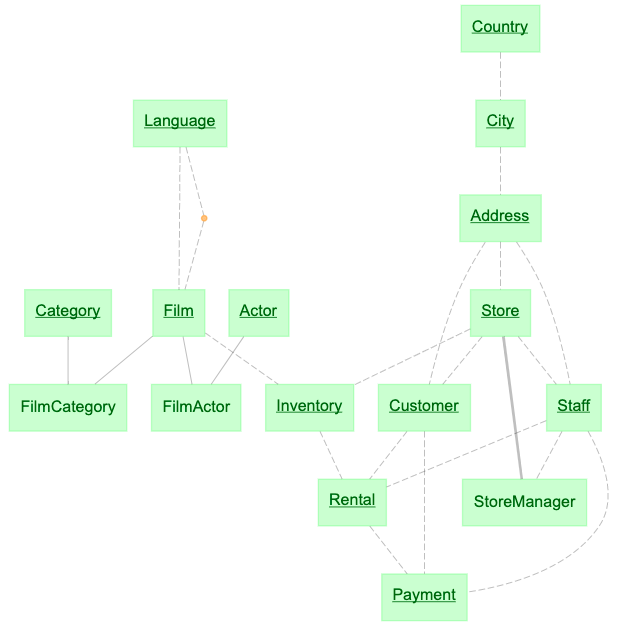
The updated schema has an extra table to represent the store managers without a cyclic dependency, enforcing the same constraints as the original schema.
Clarification 5. Rows are immutable: no UPDATE (normally)
In the original cyclic schema for the Sakila database, it was not possible to populate the Store and Staff tables with INSERTs alone when foreign keys are enforced. To populate Staff, one must have a Store and vice versa. Therefore, it would be necessary to make one of the foreign keys nullable, populate the table with NULL for the reference. After the other table is populated, then you would need to use UPDATE queries to fix the reference.
For example, we could first populate the Store table putting NULL for the manager references. Then we would populate the Staff table and then go back and use UPDATE to set the managers for the Store.
This problem does not exist for the acyclic design. One first populates the Store table, then the Staff referencing the Store, and finally populating the StoreManager table referencing both.
Therefore, the final key simplification of the DataJoint model is the assumption that tuples (or rows) in tables are immutable. They can be inserted or deleted but not updated.
The UPDATE operation is not used in normal operation. It still exists but it is understood that UPDATE is used for deliberate corrective operations, to fix mistakes but not as a normal operation in the regular workflow.
The assumption that tuples are immutable serves as the foundation for the data dependency model since foreign keys express dependencies between tuples (or entities) in the tables not simply between individual fields as is often assumed in SQL.
Summary
Sometimes less is more. By bad choices less available available, DataJoint brings focus, increases productivity, and improves communication. The result is a modern take on the relational model for the next generation of scientific computing projects.
Related posts

Agents are Brains. They Need Bodies.


When Scientific AI Forgets How It Got There

Neuropixels, Plainly Explained

Updates Delivered *Straight to Your Inbox*
Join the mailing list for industry insights, company news, and product updates delivered monthly.
