.svg)

DataJoint at CoSyNe 2026: Building AI-Ready Data Workflows for Neuroscience
.png)
This March, DataJoint’s Chief Science Officer Dimitri Yatsenko, PhD, and SciOps Engineer Milagros Marín, PhD, presented a tutorial at CoSyNe 2026 (Computational and Systems Neuroscience) called Building AI-Ready Data Workflows for Neuroscience Experiments.
The materials from this talk are now available to the public at the conclusion of this blog post.
The session brought together computational and systems neuroscientists for a hands-on look at what it takes to make scientific data infrastructure ready for AI — not someday, but now.
Here are the key ideas we shared:
1. Operational rigor is the foundation for AI in science. Dimitri opened with a provocation: How must research teams transform their work to harness AI? The answer isn't better models — it's better data discipline. Without structured schemas, enforced provenance, and reproducible computations, AI agents have nothing reliable to work with. We built on the SciOps Capability Maturity Model — a five-level roadmap from ad hoc scripts to closed-loop AI-assisted discovery — giving labs a concrete path to assess and grow their operational readiness.

2. The schema is not a record of the science — it is the science. We showed how DataJoint's relational workflow model unifies database, code, and computation into a single formal schema. Tables represent workflow steps, rows represent artifacts, and foreign keys prescribe execution order. The pipeline diagram is the database, not documentation that drifts from reality.
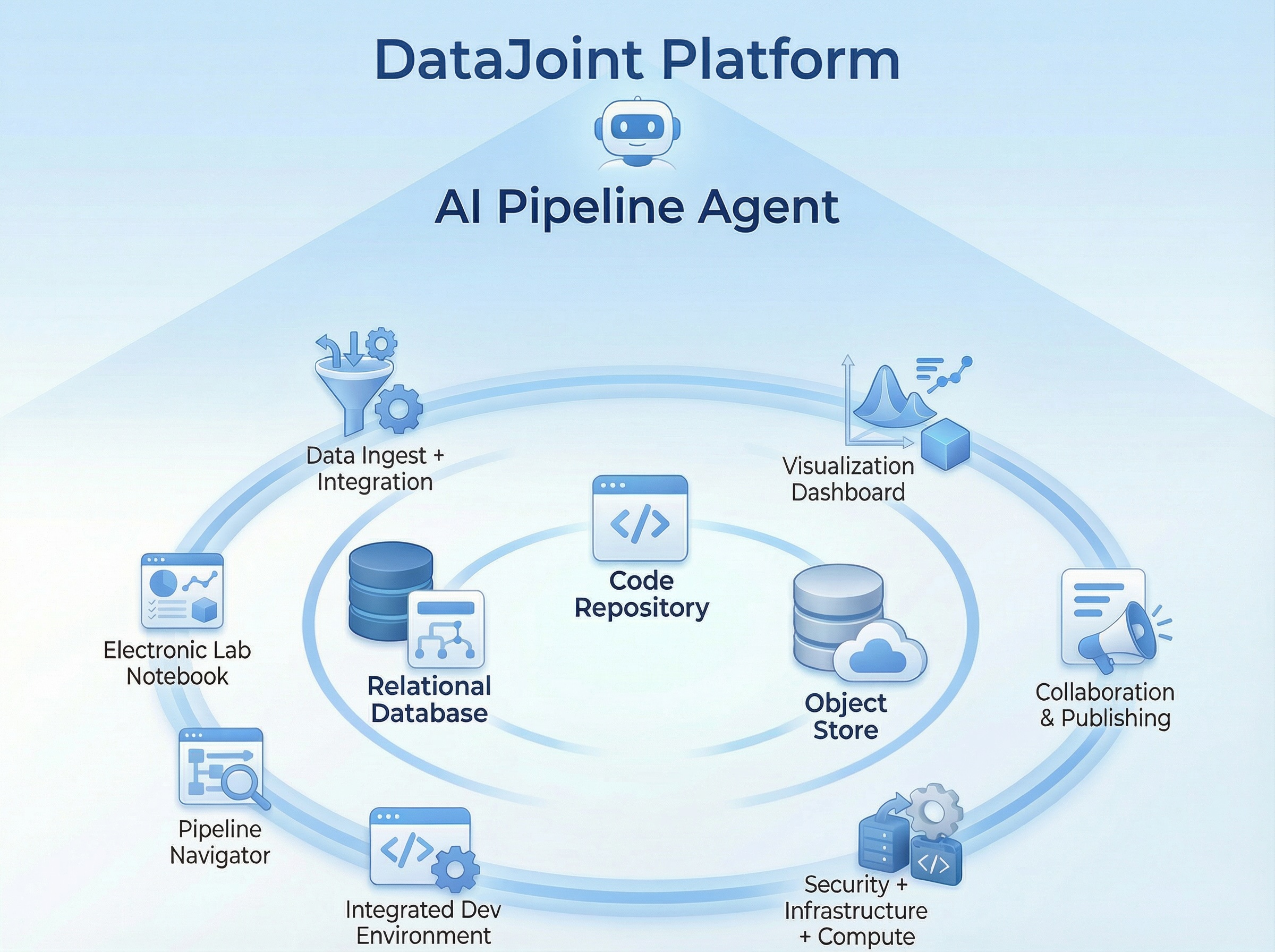
3. Three production pipelines, three scales, one platform. Milagros walked through three real-world projects running on DataJoint: ORION pipelines (brain organoids generation with four electrophysiology modalities integrated, tracking complete provenance from iPSC to spike waveform, in collaboration with the Shcheglovitov lab at the University of Utah); Project AEON (24/7 continuous behavior at the Sainsbury Wellcome Centre, processing 7 million data points per day and weeks of Neuropixels recordings); and DatJoint MoSeq pipeline (unsupervised behavioral syllable discovery in collaboration with the Datta Lab at Harvard Medical School).

4. Reproducibility validated, not just claimed. Each project included rigorous validation — positive and negative controls for ORION, dynamic schema generation tested at scale for AEON, and benchmark-matched syllable durations for MoSeq. The pipeline reproduces the science, not just the workflow.
5. AI agents can query and reason over structured pipelines. We demonstrated an AI assistant that connects directly to a DataJoint pipeline, queries behavioral data, interprets distributions, and generates scientific summaries — all made possible by a self-documenting, queryable schema. A
As Milagros put it: "Scientists direct, AI agents execute, and the data infrastructure doesn't just store science — it understands it."
6. Open-source, community-ready, publication-grade. All three project codebases are open-source. The ORION pipeline has a paper in preparation (Marín et al., 2026), and a poster will be presented at FENS Forum 2026, and AEON's preprint (Campagner et al. 2025) is out. We're building toward an ecosystem where any lab can adopt these workflows and plug in their own protocols.

It was energizing to connect with the CoSyNe community — researchers who think deeply about computation and are ready to bring that rigor to their data infrastructure. The conversation reinforced something we believe strongly: the lab of the future doesn't just manage files — it manages knowledge.
.jpg)
Missed the tutorial?

Want to explore what AI-ready workflows look like for your lab? Visit https://docs.datajoint.com or write me an email at milagros@datajoint.com to build AI-ready infrastructure for labs and institutions.
Trusted Data. Trusted AI. Trusted Science.
Related posts


DataJoint at SfN 2025

DataJoint at the PharmStars PharmaTech Innovation Summit


DataJoint at Minneapolis: Building AI-Ready DataOps for Modern Neuroscience
Updates Delivered *Straight to Your Inbox*
Join the mailing list for industry insights, company news, and product updates delivered monthly.
